P2Engine is a framework + runtime to build,
run, and evaluate multi-agent systems. Extended with the Canton
Network to enable monetary incentives, payments, and audits.
P2Engine is a framework, it is my capstone project, my
master’s thesis, where I explored multi-agent systems and related
topics. In the thesis (which you can read
here), I took a more collective/system level view on what makes systems
autonomous, and landed on four pillars I consider to be essential to
making a system fully autonomous: orchestration, observability,
adaptation, and auditability.
Just to note: the framework itself is only a step toward the
bigger ideas/visions I explore here in the article/thesis.
The framework is a backbone, a foundation to build on.
The research was grand, and I dabbled into plenty of
topics/people/stuff, not all of which made it into the thesis. In
this article, I’d like to share some of those extra thoughts, ideas,
and findings.
And even still, there’s a lot I wish I could have squeezed in, more
about systems + autonomy theory I wanted to sprinkle into the
thesis, more of my research tangents I wanted to cover in this
article, and more coding I wanted to do on P2Engine. But at some
point you have to draw that line, call it done, and move on to the
next thing... at least for now.
It’s a long ramble from here, this article is a long exploratory
dive, so if you want, jump to any part that interests you, and if
something here sparks an idea or a question, I’d love to hear from
you, email me at
adam.sioud@protonmail.com
or send me a message on
X (@gustofied).
Genesis
It did not begin as a multi-agent system (MAS) project. The thesis
was originally assigned with blockchain as the topic, and I shaped
it into a project to build a secondary market for tokenized assets.
For this, I ended up using
Canton Network
and
DAML
(jump to Ledger on why). While working on it,
I explored common Canton/DAML concepts such as multi-party
applications, workflows, interoperability, and atomicity.
Meanwhile, on the AI and LLM side, I was on X, using ChatGPT myself
and hooked on following the constant LLM trends. By late autumn, I
began reading more about agents, and at this time, one of the things
people were saying was that these "agents" people were building,
were not agents, they were more like pre-defined workflows.
This chatter, combined with DAML's concept of workflows, sparked an
idea: Workflows are hard-wired calls between LLM outputs, wouldn’t
it be fitting to model them as DAML contracts? The parties in a
workflow could decide what data to share, level of privacy, what the
flow is, whether a payment should occur once the workflow was
completed, and all of this could be captured in a DAML contract.
This was the idea that marked the transition of what the project was
to become.
Pivot
I transitioned the project into building something with LLMs, and
while blockchain was the initial topic, all focus suddenly became
just looking into LLMs, the new hot topic of agents, multi-agent
systems, reading papers, searching on X etc. And with all that
reading and search, my ideas of what I wanted to build were evolving
and changing fast.
My idea of what to build kept shifting every week, sometimes even
every day, but at some point, I had to settle on something. New and
better models kept coming, some smaller, some faster, some with
bigger context windows, others more specialized. And more
applications and systems appeared. As a quick throwback to show how
fast things were (and still are) moving,
Magentic One
was released around that time, and that was less than a year ago. It
just illustrates how much change, how many new applications, and how
much evolving is going on, things look cool one week, and by the
next week, not so much, forgotten. With all this in mind, and the
discussions I was following, there were three things that I wanted:
to build something that would not just become obsolete when a new
and better model came, to build workflows that were not too rigid,
that felt more "agentic", would this be possible in DAML contract?
hmm. And to have an interest in specialized models and facilitate
for them, a bet on not one god model, but many specialized, and
perhaps specialized models that work together. So in the end, I
landed on multi-agent systems as the main topic of research, since
that really captured what I was interested in.
Marketplace
With my goals clearer and my scope a bit narrower, I started
thinking about what this multi-agent system that I was going to
build might look like. I was also anchored to integrating blockchain
into the multi-agent system. With that anchor, I then came up with
my final vision for my thesis and what I wanted to do: I imagined
building a marketplace, a kind of Fiverr-esque platform where agents
and tasks could be matched.
This way, by being a marketplace, I found a use case for the
atomicity and the 24/7 payment rail of a blockchain ledger, and thus
it became a meaningful blockchain integration, not just smashing
agents and crypto together.
It would be a platform offering a diverse set of agents from
different vendors. A user could choose a single agent or combine
teams of specialized agents, each skilled at their own tasks,
potentially making the team more effective than any single agent
alone. Vendors would get paid, while users would get access to the
agents best suited for their needs.
Area of Research
From this vision, several research questions emerged: How would you
orchestrate such teams? How would the platform orchestrate itself?
How would you do the routing and the matching between the task and
the agent?
When it came to orchestration, the heart of the marketplace, you
could say, it became the main iterative coding and research problem
(jump to P2Engine
to read about that). After all, orchestration is what really defines
how a multi-agent system behaves, how it coordinates.
Routing, on the other hand, was where I initially found myself most
curious. One option could be an LLM. At this time I was reluctant
because of latency and costs, another option could be a semantic
router based on relevance. This was a topic I explored in a mock
thesis proposal I wrote
see pdf. The router could also route based on merit stats evals, or the
router could just be a basic selection mechanism where you choose
which agent you want, or which tasks to assign to the agent you want
to use.
I will return to routing later when we are going to look at what I
call
The Learned Router, but as stated
with agents, multi-agent systems, the agent frameworks, the key
definer is orchestration and it was the biggest coding focus to make
things work. Still, the idea of the router always remained in the
back of my mind, and that line of thought eventually gave rise to a
new concept, The Market-Based Router.
Okay then, this was the idea, the vision and concepts I had in mind.
Is P2Engine now a marketplace? Is that what I built? No. But many of
my technical decisions, and much of what was built, was anchored in
that vision and shaped by the biases I carried from this early
genesis period. Ultimately, P2Engine could serve as the backbone for
such a marketplace, because at the end of the day, a marketplace is
just one large multi-agent system.
Systems
In addition to working through the concrete challenges of
orchestration and routing, I found myself drawn to thinking about
systems and general systems theory. It’s not so tangible, not so
easy to apply, more abstract, but definitely insightful.
The multi-agent system, the marketplace as envisioned, has many
pieces; it is basically a group of interacting parts that work
together for some purpose and adapt to their environment. Its
behavior comes from interactions among the parts, not from any
single part, much like an ant colony, a flock of birds, or a
company.
From this perspective, I leaned on a few core ideas from systems
theory: holism and emergence (the whole is more than the sum of its
parts and new properties can appear that you can’t predict from
parts alone), interdependence (a change in one part can ripple
through the system in nonlinear ways), and feedback (loops that
amplify or stabilize behavior). In the context of multi-agent
systems, this naturally leads to thinking about aligning incentives
so that one individual agent’s objectives support the system’s
overall goals.
Out of this thinking came four pillars I consider essential for any
MAS that aims to be truly “agentic”, aims to be fully autonomous:
orchestration (coordination that can self-organize rather than
follow a rigid plan), observability (visibility into what is
happening and why), adaptation (learning through feedback loops at
both agent and system levels), and auditability (records and
incentives that keep actions accountable).
These pillars reinforce each other: orchestration without
observability becomes a black box, adaptation without auditability
risks chaos, and observability without adaptation leaves you with a
system that never learns. Together they bridge the gap between
individual agent capabilities and collective system performance,
turning a loose set of agents into a coherent evolving multi-agent
system.
And that’s ultimately the goal: to create a multi-agent system, a
marketplace that isn’t rigidly routed but is increasingly
autonomous, observable, and capable of learning and improving over
time. And now it’s not just the individual agents (models) that
improve, but the entire system itself, which is designed to keep on
getting better.
Much of this framing draws inspiration from systems theory and
complexity science, thinkers like Bertalanffy, Wiener, Holland,
Skyttner, and others.
Collective Intelligence
And when exploring systems, I found myself especially interested in
collective intelligence. The idea that groups can often produce
better results than individuals, that they might be easier to align,
and in some ways easier to observe, felt directly relevant to what I
wanted to achieve. I liked the thought that a MAS might not only be
more powerful but also more controllable when agents are seen as a
collective rather than as separate individuals. A project with
similar ideas and goes a bit deeper is over here on
Manifund, very cool. In addition, I did read plenty of Collective
Intelligence x Agents stuff and one of the nicer reads was this one,
Collective Intelligence, Multi Agent Debate, & AGI
by Michael Dempsey. I also noted some more collective intelligence
sources at the end, see
Collective Intelligence.
In the envisioned marketplace, as stated, I didn’t just picture
single agents working in isolation. I imagined users being able to
assemble teams of agents to tackle a task together. A task could be
decomposed into several subtasks, each handled by the agent best
suited for it, one agent specialized in X, another in Y. If the
marketplace was populated with a diverse set of specialized agents,
how could they be combined into groups and get them to work
together? That question led me to think about how we actually
organize human teams. I considered introducing “group exercises” for
agents, using methods like the Delphi method, polling, idea trees,
and watch what dynamics emerge. A great site on group exercises
which is of great inspiration and learning is
Methods and Tools for Co-Producing Knowledge. The idea was to map human approaches onto agents, just like we
already make them read PDFs line by line using tool usage. Put
simply: design agent collaboration the way we design human
collaboration.
At the same time, group exercises raise an interesting question:
when you look at high-performing human teams, do they actually sit
down and do exercises like these, or do they just get the job done?
Hmmm.
To tap into collective intelligence further, I became interested in
how to mimic the kinds of emergent behavior seen in nature and
society, intelligence that shows up without a single central
controller. That led me to wonder: how does the intelligence of
entire groups actually get signaled and turned into decisions? And
could those same mechanisms be mapped onto MAS? Most collective
decision-making ultimately comes down to voting, polling, or other
ways of gathering distributed input. Some of the clearest real-world
examples of CI at work are capital markets and democracy itself, and
it is markets, as some kind of incentive layer, that I’ve found
especially interesting.
Markets: The Market-Based Router
Markets act as decentralized information systems. To clarify: when I
say market here, I mean the economic layer created by the
participants themselves, sitting on top of the marketplace (pardon
for making it a bit confusing). Either way, a marketplace of just
agents, tasks, data resources, and compute can easily turn stale.
There are no incentives, no “liquidity” to make things move and
connect. This is where the market, and its participants, come in.
It is the market participants that make markets powerful, in that
prices reflect individual beliefs. When combined, these beliefs form
a collective signal. And because participants are incentivized not
to lose their own money, the market naturally pushes toward the best
solution. (This statement can be argued such that the longer the
time frame, the truer it becomes, approaching truth in the limit;)
). Prices let decisions be coordinated without a central planner,
efficiently broadcasting where demand and value exist. So in our
marketplace setting, the market could act as the global optimizer, a
search strategy, helping route tasks to the right agents and
rewarding those that perform well. Humans could guide this process
by deciding which signals to value: success rates, reputation, task
complexity, novelty. They could even build algorithms to automate
that decision-making, in line with how quants and market makers
today operate in capital markets.
This line of thinking is what led me to
OUDAU, an exchange that acts as a router where the price itself becomes
the signal. Market participants (allocators) continuously decide
which models to train, which tasks to prioritize, and how compute is
allocated. Instead of a static marketplace, OUDAU turns routing into
an allocation process, thereby making the system adaptive and
self-optimizing over time, much like capital markets. If that sounds
interesting, check out OUDAU!
The Bag of Candy Stack
AI Natives vs. Crypto Natives
On crypto and AI, it’s not something I get particularly excited about.
I see two kinds of players in this space: what I’d call the
crypto natives and the AI natives. On the AI side, you
have labs that use crypto as plumbing for decentralized training and
inference, GPU networks, verification, and making things trustless.
Examples such as
Prime Intellect,
Gensyn, and
Nous Research. Very cool stuff.
As for the crypto natives, there’s not as much that excites me here.
Still, if you’re curious, you might check out
OpenGradient. And an OG player, and always interesting,
Numerai, a crowdsourced hedge fund where data scientists build stock-market
models on encrypted data and stake on their predictions. Big fan. It’s
not directly related to what I’m building and LLMs, but in some ways
it is, especially if you think about how a market-based router might
work.
While much of the crypto space can feel noisy, with tokens and new
investment vehicles often layered on top of each other, there are
still meaningful ideas and technologies that stand out. The original
ethos has shifted [hmm need to explain this one], and real
product–market fits can be harder to identify, but not impossible. A
strong example is tokenized assets and stablecoins: they showcase
clear utility with atomic settlement, 24/7 trade, and reduced fees.
These features provide a huge edge over traditional rails, and with
that in mind, it’s also a perfect fit for the envisioned marketplace.
Ledger
This means the crypto, the blockchain, the ledger, fits right into the
project as an important piece of infrastructure to handle a key part
of what I am building. The encompassing term here is DLT, distributed
ledger technology. And as stated before, back in autumn 2024, I was
exploring the best DLT to build a secondary market. I looked at
decentralization, institutional adoption, and regulatory compliance,
and I ended up with
Canton Network.
Why Canton Network? For me, adoption is the strongest signal, not
market cap, not hype, but real utility, who they are working with, and
their ethos. It seemed to be a clear winner. And since then, they
recently just
raised another round of funding, and major players like
Goldman Sachs, along with many others, have been steadily joining the Global
Synchronizer over time.
It’s not only about Canton’s adoption, but also their rationale about
privacy sounded solid to me. Their idea of granular privacy feels way
more workable than full transparency. A good read on this is
How Canton Network Delivers Institutional-Grade Privacy, and I also recommend
Full Transparency is a Bug, Not a Feature
and
Zero-Knowledge Proofs: When Privacy Needs More. Beyond privacy, their vision about connections and not creating
silos: multi-party workflows you can model and settle end-to-end. And
their idea of a network of networks: the Global Synchronizer as the
backbone that links independent domains so assets and data move
atomically across them.
So Canton just felt more interesting than others, alternatives like
Hyperledger Fabric
or
R3 Corda. Ethereum’s ecosystem/tech was a clear option, with broad adoption
and improving regulatory clarity. But integrating it properly for the
marketplace would require a more thoughtful, thorough effort,
especially around zk-proofs, privacy, and security. In the end, I
chose an unknown player, very few have heard of Canton Network, but
I’d argue it’s the better choice. One way I found information about
Canton Network was by researching different blogs, articles, and one
of the best was
Ledger Insights, which gives excellent coverage of enterprise blockchain and DLT.
I’ve also noted some additional resources down in
Economy
section covering some of my DLT research.
It seems that in one way I’m trying to distance P2Engine from being a
crypto project, which is true, it really isn’t one, and I don’t want
it to be seen that way. But, and here comes the cliché, I have to say
there’s underlying technology here that’s genuinely interesting and
worth using, especially for an idea like the envisioned marketplace. I
also can’t ignore the fact that the project was originally anchored in
blockchain, and that DNA still has to be carried.
So that’s where I ended up, I had to pick one, and I picked Canton
Network. And picking a crypto is like picking a bag of candy, you’ll
get some bits you really like, some alright, some you hate. That’s
just how it is with crypto, there are tradeoffs, speed, privacy,
decentralization, and so on. But Canton does feel like a different
kinda bag.
Agent Frameworks
[this little section is still in the works..]
When it came to agent frameworks, I wanted to take a bare-bones
approach. I wanted maximum control and didn’t want anything hidden,
not the prompt handling, logging, orchestration logic, or anything
else a framework might abstract away. Just me, Python, and the logs. I
also picked up this ethos from reading others who tried frameworks and
later moved away from them. Over time, the frameworks seemed to create
more problems than they solved.
But although I didn’t use any framework, that doesn’t mean I didn’t
map out the ecosystem, I still wanted to learn from them and study how
they worked, what they did, their design choices.
You can explore P2Engine on
GitHub, I’ve included more detailed documentation there as well.
P2Engine became the artifact of the thesis, a framework and runtime
to build, run, and evaluate multi-agent systems. Not a marketplace?
No, but I’d argue it’s a framework that could become the engine
behind one. It turned into a bare-bones base layer that can be
stretched in different directions: a marketplace, apply learning
methods, discovery setups like
Sakana AI Scientist, testing collective intelligence coordination, an observability
and logging app, or even running it as a live multi-agent
deployment. I guess the result was shaped by me being so entangled
in all these visions and research and wanting to somehow support
them all. At the end of the day, it started as bare-bones as
possible: a Python project with LiteLLM, Redis, and Celery, and
that’s it.
And with that bare-bones strategy and big visions, the process
became iterative, with no clear idea at first of how to architect
it. Thinking in systems theory wasn’t easy to apply. Early on, I had
a big interest in event-driven architecture and the idea of treating
agents like microservices, more on this
here. And by exploring how other
Agent Frameworks approached things,
I thought I could mix and match the best ideas and build my own. But
in practice, it was way too hard, nothing concrete, more roaming
around ideas than actually getting to work. I needed a North Star,
then one day, I stumbled upon a beautiful and thoughtfully designed
blueprint by Erik on his
blogsite
which came to fully inspire P2Engine’s architecture and internals.
His architecture proposal and taste for systems, what an agent is,
the importance of tools, orchestration, reasoning, etc., really
resonated with me and helped shape P2Engine into what it is today. A
big recommendation, check out Erik’s State Machines for Agents
series. Here is
Part 1, then continue with
Part 2,
Part 3, and
Part 4.
And with that, it became really easy to build.
What It Does
In short, agents delegate tasks to each other, use tools, and earn
payments based on performance evaluations. The system provides
conversation branching and replay, automated A/B testing via
rollouts, and blockchain-based wallets for tracking transactions.
You can monitor everything through an interactive CLI and real-time
Rerun visualizations, with some runtime configuration options for
agent behavior and tools. You can create custom evaluators, tools,
agents, and design your own rollouts for testing different
configurations.
How It Works
P2Engine’s orchestration is fundamentally built on finite state
machine (FSM) principles, where each agent conversation progresses
through well-defined states with explicit transition rules.
It runs LLM-agents in discrete steps. Each step produces artifacts,
and a separate and async evaluator scores them. You can think of it
like this: the agent thinks, acts, and creates something; the
evaluator observes, scores.
Every agent maintains a stack in Redis storing complete interaction
history. Redis serves as the central coordination layer, managing
conversation state, agent registrations, session ticks, and
cross-agent communication. This enables conversation rewinding,
branch creation for alternative paths, and preserved context across
agent handoffs
Agent decisions generate "effects" (tool calls, payments,
delegations) that execute asynchronously via Celery workers.
Rollouts work by creating YAML configuration files that specify
teams, base settings, and variants. The system expands these into
individual experiments, runs them in parallel using Celery workers,
and collects the metrics.
And these rollouts unfold through the P2Engine CLI with live
progress tables, and stream to Rerun viewer for more visual
monitoring.
The Learned Router
Erik touches on the concept of a “global reasoner” in
part 4
of his State Machines for Agents series. One topic I’ve been
circling throughout this article is the router idea, and I adapt
Erik’s notion of global reasoning, where the system can learn which
agent configuration to use next, into what I call the learned
router.
The idea is straightforward: instead of hardcoding routing decisions
or relying on simple semantic matching, the system learns from
outcomes. Erik frames this at the level of selecting the next agent
configuration, and I extend it to the marketplace setting: asking
“which agent should handle this task?” The router learns from past
performance, success rates, user feedback, and more, building a
policy that captures what actually works rather than what we think
should work.
The learned router rivals the market-based router I discussed
earlier. Where the market-based router uses economic signals and
price discovery to coordinate routing decisions, the learned router
uses learning to optimize based on observed outcomes. But both
approaches aim to solve the same fundamental problem: moving beyond
rigid routing to systems that learn and adapt to the real world.
What makes this particularly compelling is that it turns
orchestration from a design problem into a learning problem. Instead
of trying to anticipate all possible routing scenarios upfront, the
system continuously improves its routing decisions based on
real-world outcomes. And since P2Engine implements this learned
router approach in its current framework, it provides the foundation
and a short route to test and validate these concepts on the
envisioned marketplace.
Showcase
Here are some core functionalities of P2Engine.
Agent Delegation — Agents delegate tasks to
sub-agents. Conversation context is preserved across all agent
interactions.
Branch Rewind — Rewind conversations to any point
and explore alternative paths. Switch between different
conversation branches.
Rollouts — Run multiple agent configurations
simultaneously, (A/B testing). Compare metrics (artifacts, reward,
token usage, costs, ledger transactions, speed, and more) and
visualize results in real time.
Ledger — Agents have wallets and can transfer
funds. All transactions are recorded with complete audit trails.
Architecture
Let’s learn a bit about P2Engine through these diagrams (more details
in the
repo).
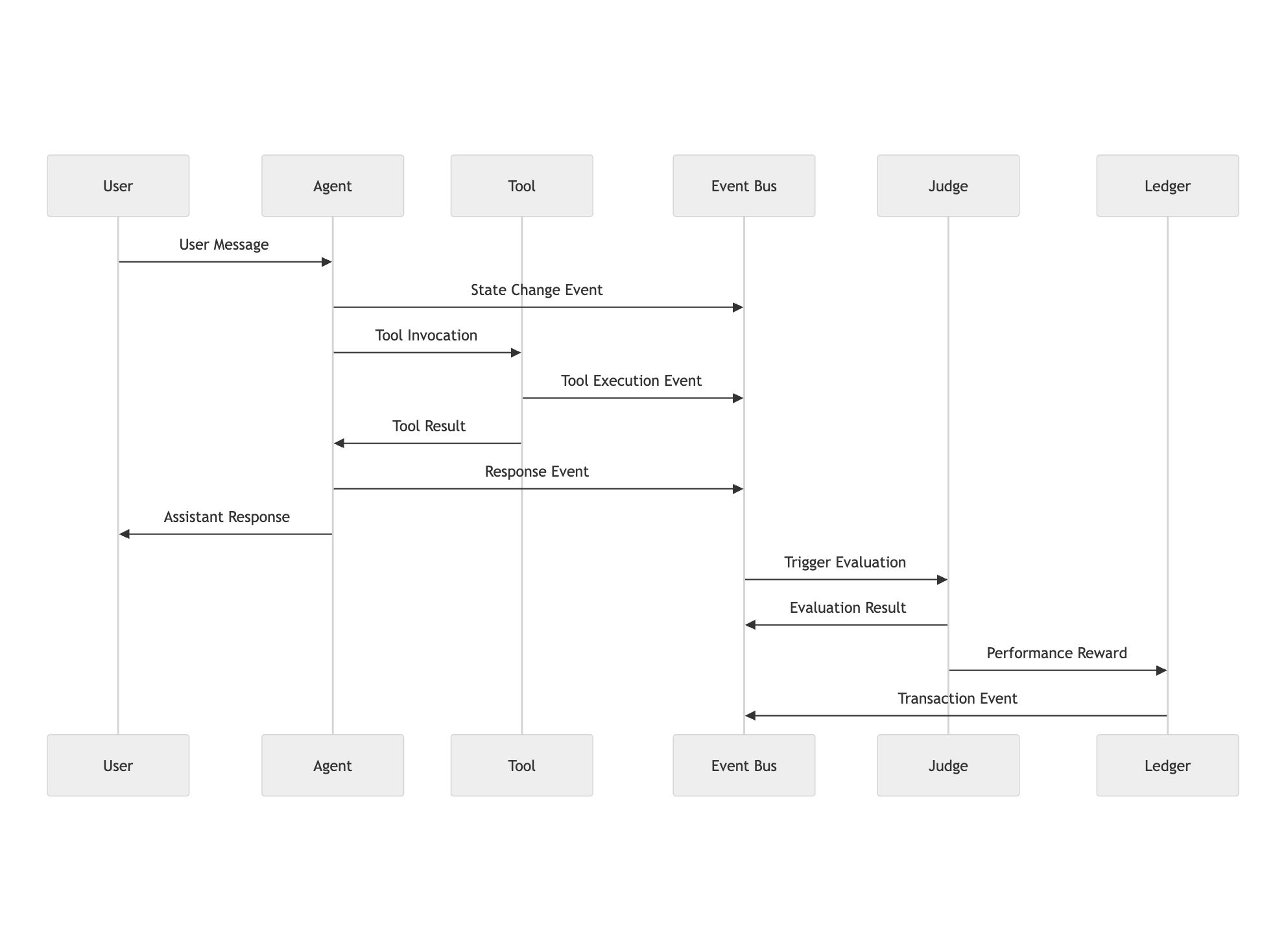
Execution Sequence — The execution process
follows the interactions shown in the sequence diagram,
illustrating how P2Engine operates end-to-end.
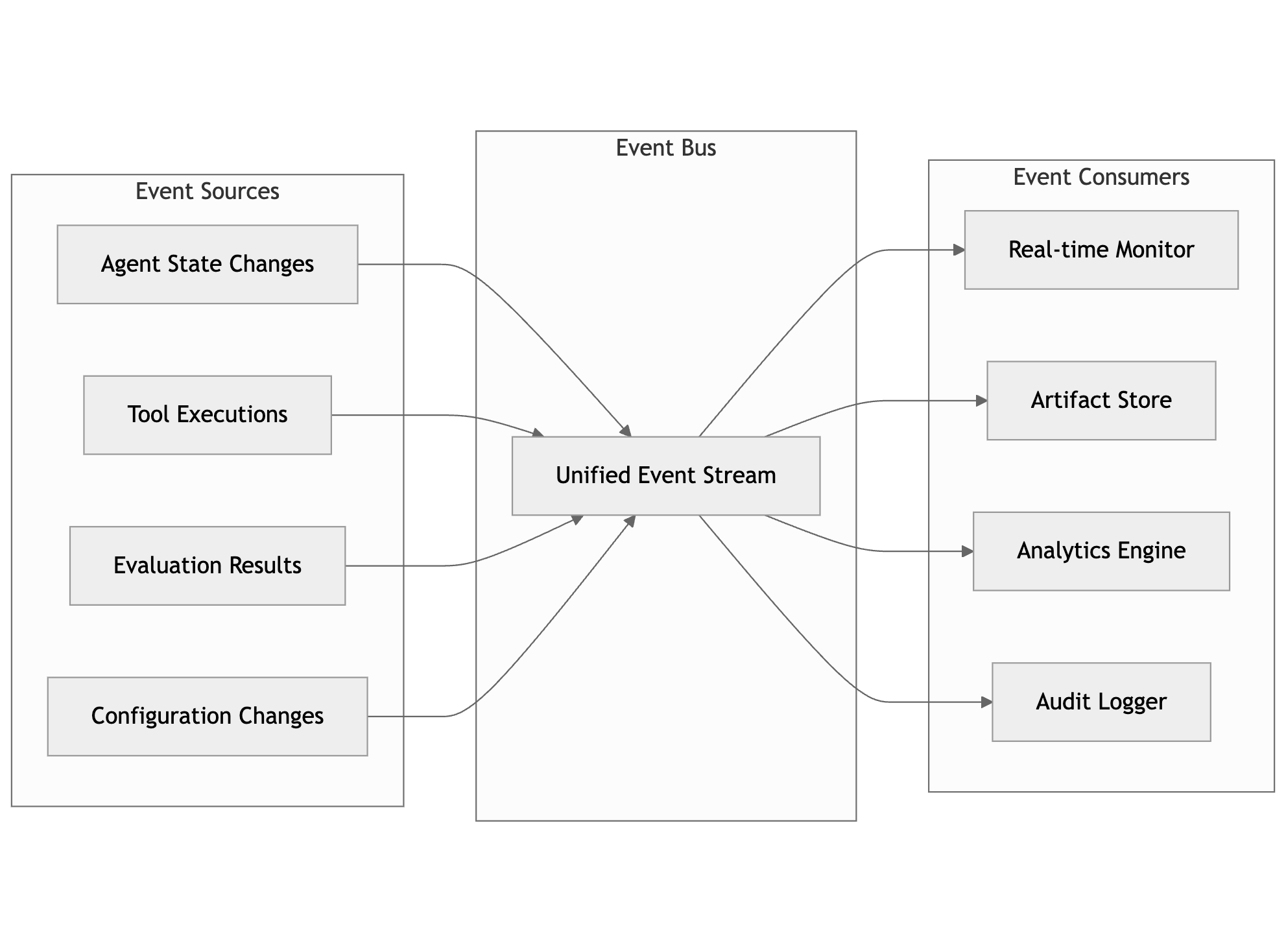
Unified Event Stream — The unified event stream
powers monitoring, debugging, and analysis by capturing every
significant system event.
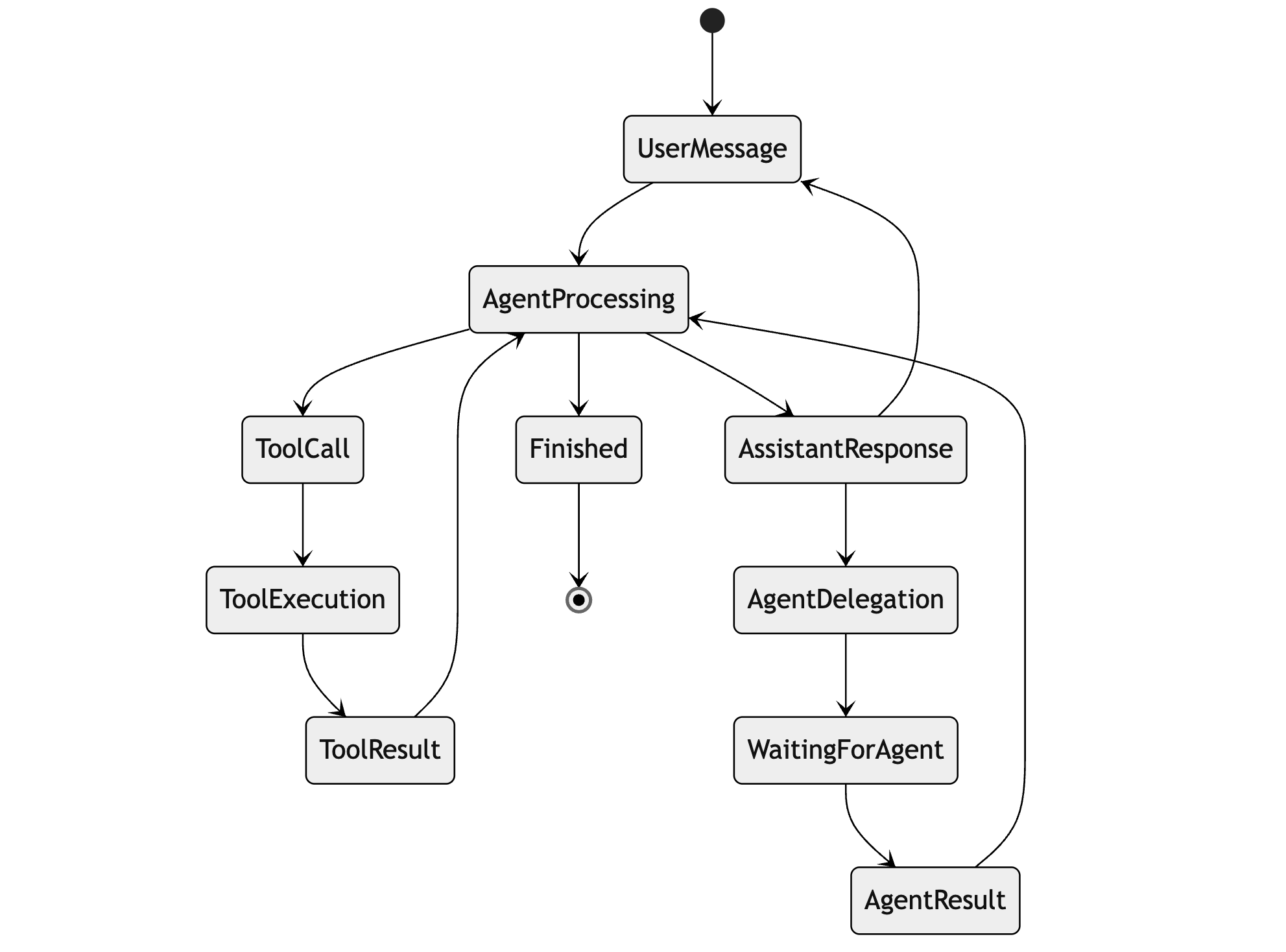
FSM — P2Engine’s execution is built on FSM
principles: conversations move through explicit states with
defined transition rules. Deterministic, debuggable, and
flexible for dynamic routing and asynchronous operations.
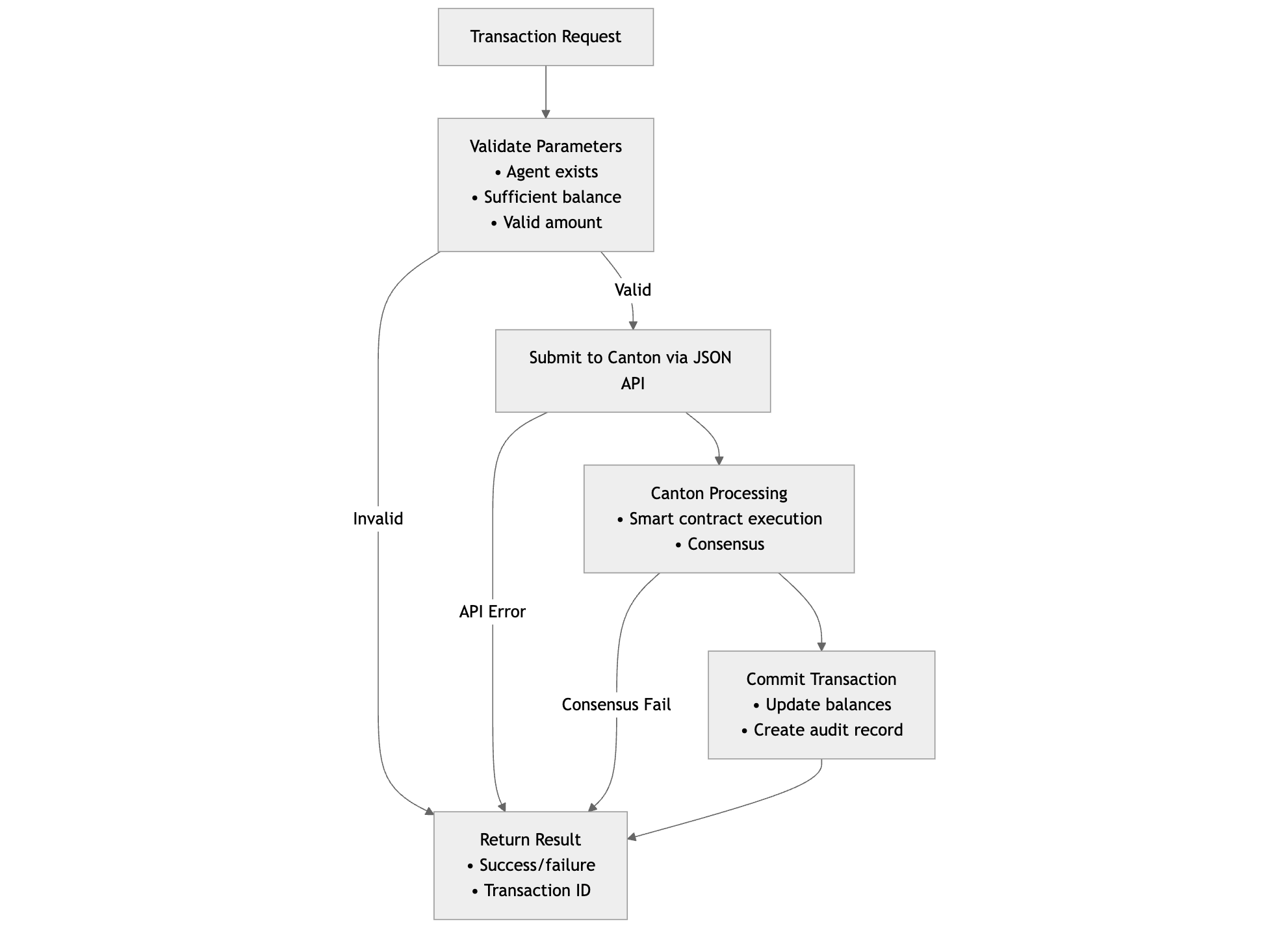
Transaction Flow — Every financial operation
follows a consistent pattern with validation, execution, and
recording.
Future
I like the idea of turning P2Engine into a proper open-source
framework that contributes a piece of the puzzle in the agent space,
adopting and following the idea of Will
here.
Which direction it takes, time will tell. In the
GitHub README
I outline a possible direction, a near-term plan: close the learning
loop and implement system-prompt learning. Either way, it’s time to
scope P2Engine down further and choose the next path. The plumbing
is here. I’m currently exploring RL and agent interaction in
OWL,
and experimenting with the market-based router at
OUDAU. What I learn
from them may inspire, and point me toward the direction P2Engine
should take.
Contact me if you’re interested in discussing any of this. Thank you
for reading.
Resources
A little reservoir of stuff I suggest to explore further, people to
follow, articles to read, tools/services and ideas to test.
[still filling in..]
To develop a proper system, applying learnings from Distributed
Systems, Microservices, and EDA will be the way to go. The idea of
treating agents as microservices, and tools as microservices, is
tasteful. I’d look into Erlang, Erlang FSM/Mailbox, Elixir, and
Golang. Instead of building agents with common agent frameworks,
first look into these languages and their ways of doing things.
There are services who help with this too:
Temporal,
Restate,
Trigger.dev,
Inngest.